Reduce GPU costs by 70%
Meet latency SLOs automatically
Run any vLLM model or LoRA
Shared inference APIs
No guaranteed SLOs in a shared API
No control over prompts, weights, or logs leaving your environment
Limited model selection, fixed pre-configs
Overprovisioned for SLOs, or cost-effective without them
With Rivvr
Custom SLOs, held automatically, even under traffic bursts
Runs inside your own AWS account
Any vLLM base model, fine-tune, LoRA, or quantization
Continuously optimized for your SLO and cost targets
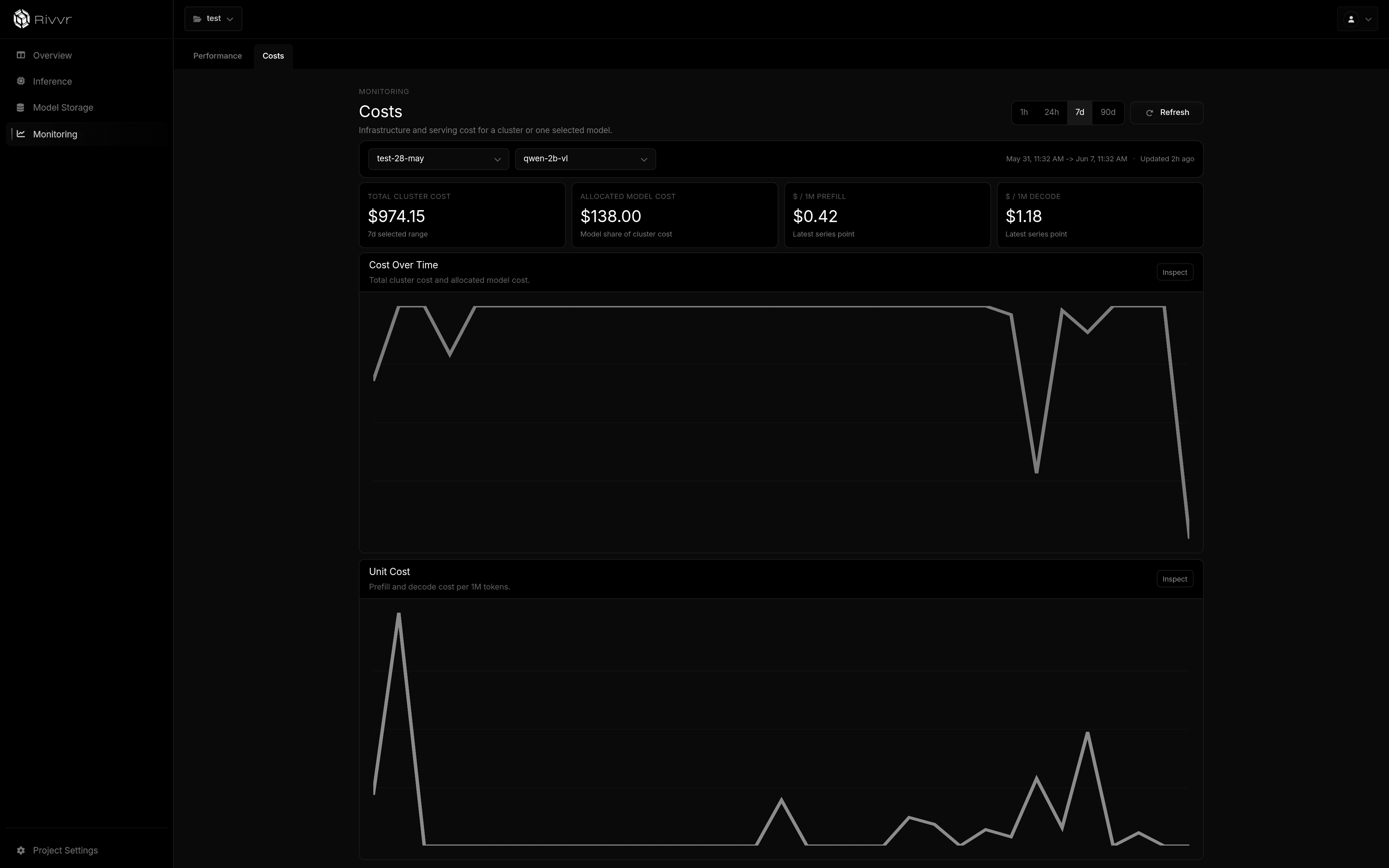
How is this different from managed platforms?
Rivvr gives you the managed service experience — no infra to run, no scaling rules to tune — but inside your own AWS account. You keep full control over security, SLOs, and cost, without the operational overhead.
How is this different from AIBrix or NVIDIA Dynamo?
Two things. First: you don't operate anything — Rivvr runs as a managed platform inside your AWS account, unlike the software your team deploys and maintains. Second: a different operational model. AIBrix and Dynamo ask you to configure autoscaling, profiling, and dozens of other parameters. Rivvr asks for two — your SLO and your cost guardrail. Set those, and you're running.
Isn't spot capacity risky for something with an SLO?
Alone, yes — spot can be reclaimed with little warning. Rivvr's cluster spans multiple GPU types, so there's rarely just one spot pool to lose — if one type is reclaimed, another picks up the load, with on-demand as the fallback. More pools, more savings, no interruption risk.
Where does Rivvr run?
Inside your AWS account, behind your VPC. Inference traffic, data, and model weights never leave your environment.
How is Rivvr priced?
Rivvr is priced as a management layer based on GPUs under orchestration. You pay AWS directly for infrastructure; Rivvr charges a separate management fee.
Do I need to change my integration code?
No. Rivvr uses an OpenAI-compatible API. Most teams point their existing client at a new endpoint, and nothing else changes.
Does Rivvr modify or compress my models?
No. Rivvr doesn't touch model weights. Optimization happens at the orchestration, placement, and infrastructure layers.
What models does Rivvr support?
Any Large Language Model served by vLLM, up to 400B parameters. If you're running something larger or unusual, let's talk.
What inference engines are supported?
Rivvr uses a vLLM-compatible runtime.
What GPUs are supported?
NVIDIA GPUs with CUDA compute capability 7.0 or higher — including L4, L40S, A10G, T4, A100, H100, H200, B200, B300, V100.